
引用
调试
-
本地 debug 时 可以通过 fiddler 抓取到请求 es 服务的 http 请求。
-
也可可以在代码中抓取到 request 和 response
var settings = new ConnectionSettings(pool); //在创建 client 时开启设置; //正式环境建议关闭,占用资源 settings.DisableDirectStreaming(true); var client=new ElasticClient(settings); var result=client.Search(....); var requestStr = System.Text.Encoding.Default.GetString(result.ApiCall.RequestBodyInBytes); var responseStr = System.Text.Encoding.Default.GetString(result.ApiCall.ResponseBodyInBytes); _log.Debug(requestStr + " " + responseStr);
存储结构:
在Elasticsearch中,文档(Document)归属于一种类型(type),而这些类型存在于索引(index)中.
类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
DB 使用过程:创建数据库->创建表(主要是设置各个字段的属性)->写入数 ES 使用过程:创建索引->为索引 maping 一个 Type(同样是设置类型中字段的属性)->写入数
客户端语法
链式 lambda 表达式( powerful query DSL)语法
s => s.Query(q => q .Term(p => p.Name, "elasticsearch") )
对象初始化语法
var searchRequest = new SearchRequest<VendorPriceInfo> { Query = new TermQuery { Field = "name", Value = "elasticsearch" } };
Connection 链接
//单 node Var node = new Uri(“……”); var settings = new ConnectionSettings(node); //多 uris Var uris = new Uri [] { new Uri(“……”), new Uri(“……”) }; var pool = new StaticConnectionPool(uris); //多 node Var nodes = new Node [] { new Node (new Uri(“……”)), new Node (new Uri(“……”)) }; //链接池 var pool = new StaticConnectionPool(nodes); var settings = new ConnectionSettings(pool); var client = new ElasticClient(settings);
注:nest 默认字段名首字母小写,如果要设置为与 Model 中一致,在创建 client 时按如下设置。(强烈建议使用该设置,避免造成字段不一致)
var settings = new ConnectionSettings(node).DefaultFieldNameInferrer((name) => name);
Connection Settings
var settings = new ConnectionSettings(pool); //验证 未开启 //settings.BasicAuthentication("username", "password"); //验证证书 //settings.ClientCertificate(""); //settings.ClientCertificates(new X509CertificateCollection()); //settings.ServerCertificateValidationCallback(); //开启 第一次使用时进行嗅探,需链接池支持 //settings.SniffOnStartup(false); //链接最大并发数 //settings.ConnectionLimit(80); //标记为死亡节点的超时时间 //settings.DeadTimeout(new TimeSpan(10000)); //settings.MaxDeadTimeout(new TimeSpan(10000)); //最大重试次数 //settings.MaximumRetries(5); //重试超时时间 默认是 RequestTimeout //settings.MaxRetryTimeout(new TimeSpan(50000)); //禁用代理自动检测 //settings.DisableAutomaticProxyDetection(true); //禁用 ping 第一次使用节点或使用被标记死亡的节点进行 ping settings.DisablePing(false); //ping 超时设置 //settings.PingTimeout(new TimeSpan(10000)); //选择节点 //settings.NodePredicate(node => //{ // // return true; // //}); //默认操作索引 //settings.DefaultIndex(""); //字段名规则 与 model 字段同名 //settings.DefaultFieldNameInferrer(name => name); //根据 Type 获取类型名 //settings.DefaultTypeNameInferrer(name => name.Name); //请求超时设置 //settings.RequestTimeout(new TimeSpan(10000)); //调试信息 settings.DisableDirectStreaming(true); //调试信息 //settings.EnableDebugMode((apiCallDetails) => //{ // //请求完成 返回 apiCallDetails //}); //抛出异常 默认 false,错误信息在每个操作的 response 中 settings.ThrowExceptions(true); //settings.OnRequestCompleted(apiCallDetails => //{ // //请求完成 返回 apiCallDetails //}); //settings.OnRequestDataCreated(requestData => //{ // //请求的数据创建完成 返回请求的数据 //}); return new ElasticClient(settings);
不同的连接池类型
//支持 ping 说明能够发现节点的状态 //支持嗅探 说明能够发现新的节点 //应用于已知集群,请求时随机请求各个正常节点,支持 ping 不支持嗅探 IConnectionPool pool = new StaticConnectionPool(nodes); //推荐使用 //IConnectionPool pool=new SingleNodeConnectionPool(nodes[0]); //可动态嗅探集群 ,随机请求 支持嗅探、ping //IConnectionPool pool = new SniffingConnectionPool(nodes); //选择一个可用节点作为请求主节点,支持 ping 不支持嗅探 //IConnectionPool pool = new StickyConnectionPool(nodes); //选择一个可用节点作为请求主节点,支持 ping 支持嗅探 //IConnectionPool pool=new StickySniffingConnectionPool(nodes);
操作目标索引/类型选择
指定索引
//执行操作时指定索引 client.Search<VendorPriceInfo>(s => s.Index("test-index")); client.Index(data,o=>o.Index("test-index")); ....
指定类型
默认类型为索引数据的类名(自动转换为全小写,规则可自定义)。
如果特性设置Name[ElasticsearchType(Name = “datatype”)]则使用该名称。
//主动指定 client.Index(data, o => o.Type(new TypeName() { Name = "datatype", Type = typeof(VendorPriceInfo) }));
数据模型特性
特性可以设置数据在 es 中的类型、名称、是否索引、分词、格式化等信息。
应用于第一次创建索引后进行映射时。
重要特性:
-
[ElasticsearchType(Name = “文档的类型”,IdProperty = “文档的唯一键字段名”)] -
[Number(NumberType.Long,Name = “Id”)]数字类型 +名称 -
[Keyword(Name = “Name”,Index = true)]不需要分词的字符串,name=名称,index=是否建立索引 -
[Text(Name = “Dic”, Index = true,Analyzer = “ik_max_word”)]需要分词的字符串,name=名称,index=是否建立索引,Analyzer=分词器
/// <summary> /// 5.x 特性 /// </summary> [ElasticsearchType(Name = "TestModel5",IdProperty = "Id")] public class TestModel5 { [Number(NumberType.Long,Name = "Id")] public long Id { get; set; } /// <summary> /// keyword 不分词 /// </summary> [Keyword(Name = "Name",Index = true)] public string Name { get; set; } /// <summary> /// text 分词,Analyzer = "ik_max_word" /// </summary> [Text(Name = "Dic", Index = true)] public string Dic { get; set; } [Number(NumberType.Integer,Name = "State")] public int State { get; set; } [Boolean(Name = "Deleted")] public bool Deleted { get; set; } [Date(Name = "AddTime")] public DateTime AddTime { get; set; } [Number(NumberType.Float,Name = "PassingRate")] public float PassingRate { get; set; } [Number(NumberType.Double, Name = "Dvalue")] public double Dvalue { get; set; } }
索引操作
创建
client.CreateIndex("test2"); //基本配置 IIndexState indexState=new IndexState() { Settings = new IndexSettings() { NumberOfReplicas = 1,//副本数 NumberOfShards = 5//分片数 } }; //创建索引 先不 maping client.CreateIndex("test2", p => p.InitializeUsing(indexState)); //创建并 Mapping client.CreateIndex("test-index3", p => p.InitializeUsing(indexState).Mappings(m => m.Map<VendorPriceInfo>(mp => mp.AutoMap())));
注:索引名称必须小写
判断
client.IndexExists("test2");
删除
client.DeleteIndex("test2");
索引创建、maping、设置别名、别名操作
/// <summary> /// 创建索引 /// </summary> private void CreateIndex(string indexName) { if (!_client.IndexExists(indexName).Exists) { IndexState indexState = new IndexState { Settings = new IndexSettings { NumberOfReplicas = _replicas, //副本数 NumberOfShards = _shards //分片数 } }; //创建并设置 _client.CreateIndex(indexName, p => p .InitializeUsing(indexState) .Mappings(m => m.Map<EsDataModel>(mps => mps.AutoMap())) .Aliases(a => a.Alias(_indexAliase + "_manager")) ); //map //_client.Map<EsDataModel>(m => m.Index(indexName).AutoMap()); #region 别名操作 Action addAlias = () => { _client.Alias(a => a.Add(d => d.Index(indexName).Alias(_indexAliase))); }; //该别名是否存在 if (!_client.AliasExists(s => s.Name(_indexAliase)).Exists) { addAlias(); return; } var result = _client.GetAlias(a => a.Name(_indexAliase)); //该别名下所有 索引 if (result.Indices == null) { addAlias(); return; } var indices = result.Indices.Select(index => index.Key).Select(dummy => (IndexName)dummy).ToArray(); //该别名下所有 索引 if (indices.Length <=0) { addAlias(); return; } //删除其它老的索引的别名 //添加到新的索引上 Func<AliasRemoveDescriptor, IAliasRemoveAction> removeSelector = d => { foreach (var index in indices) { d.Alias(_indexAliase).Index(index.Name); } return d; }; _client.Alias(a => a // 删除 别名 .Remove(removeSelector) //添加 别名 .Add(d => d.Index(indexName).Alias(_indexAliase)) ); #endregion } }
映射
如果创建索引时没有进行 maping 操作,可以再单独 maping,已经确定类型的字段无法更改,可以新增。
//根据对象类型自动映射 var result = _client.Map<TestModel5>(m => m.AutoMap()); //手动指定 var result1 = _client.Map<TestModel5>(m => m.Properties(p => p.Keyword(s => s.Name(n => n.Name).Index(true))));//Keyword 类型
新增映射字段
//新增字段 var result = _client.Map<TestModel5>(m => m .Index(indexName) .Properties(p => p .Keyword(s => s .Name("NewField") .Index(true)) .Text(s=>s .Name("NewFieldText") .Index(false)) ) );
注:映射时已存在的字段将无法重新映射,只有新加的字段能映射成功。所以最好在首次创建索引后先进性映射再索引数据。
注:映射时同一索引中,多个类型中如果有相同字段名,那么在索引时可能会出现问题(会使用第一个映射类型)。
注:如果没有特殊需求,且字段没有过多的重叠,一个索引建议只存放一个类型的数据。
数据
添加单条数据
//写入数据,指定索引 _client.Index(data, s => s.Index(indexName)); //指定索引、类型 _client.Index(data,s=>s.Index(indexName).Type("TestModel5")); //写入数据,指定索引 _client.IndexMany(datas, indexName); //指定索引、类型 _client.IndexMany(datas, indexName, "TestModel5");
删除数据
DocumentPath<TestModel5> deletePath = new DocumentPath<TestModel5>(7); _client.Delete(deletePath,s=>s.Index(indexName)); _client.Delete(deletePath,s=>s.Index(indexName).Type(typeof(TestModel5))); _client.Delete(deletePath,s=>s.Index(indexName).Type("TestModel5")); IDeleteRequest request = new DeleteRequest(indexName, typeof(TestModel5), 7); _client.Delete(request); //1.x 中有 2.x 中需要安装插件 5.x 中又回来了 _client.DeleteByQuery<TestModel5>( s =>s .Index(indexName) .Type("TestModel5") .Query(q =>q.Term(tm => tm.Field(fd => fd.State).Value(1))));
更新数据
更新所有字段
DocumentPath<VendorPriceInfo> deletePath=new DocumentPath<VendorPriceInfo>(2); Var response=client.Update(deletePath,(p)=>p.Doc(new VendorPriceInfo(){vendorName = "test2update..."})); //或 IUpdateRequest<VendorPriceInfo, VendorPriceInfo> request = new UpdateRequest<VendorPriceInfo, VendorPriceInfo>(deletePath) { Doc = new VendorPriceInfo() { priceID = 888, vendorName = "test4update........" } }; var response = client.Update<VendorPriceInfo, VendorPriceInfo>(request);
更新部分字段
IUpdateRequest<VendorPriceInfo, VendorPriceInfoP> request = new UpdateRequest<VendorPriceInfo, VendorPriceInfoP>(deletePath) { Doc = new VendorPriceInfoP() { priceID = 888, vendorName = "test4update........" } }; var response = client.Update(request);
更新部分字段
IUpdateRequest<VendorPriceInfo, object> request = new UpdateRequest<VendorPriceInfo, object>(deletePath)
{
Doc = new
{
priceID = 888,
vendorName = " test4update........"
}
};
var response = client.Update(request);
//或
client.Update<VendorPriceInfo, object>(deletePath, upt => upt.Doc(new { vendorName = "ptptptptp" }));
注:更新时根据唯一 id 更新
更新时使用本版号加锁机制
//查询到版本号 var result = _client.Search<TestModel5>( s => s.Index(indexName) .Query(q => q.Term(tm => tm.Field(fd=>fd.State).Value(1))).Size(1) .Version()//结果中包含版本号 ); foreach (var s in result.Hits) { Console.WriteLine(s.Id + " - " + s.Version); } var path = new DocumentPath<TestModel5>(1); //更新时带上版本号 如果服务端版本号与传入的版本好相同才能更新成功 var response = _client.Update(path, (p) => p .Index(indexName) .Type(typeof(TestModel5)) .Version(2)//限制 es 中版本号为 2 时才能成功 .Doc(new TestModel5() { Name = "测测测" + DateTime.Now }) );
搜索
基本搜索
var result = _client.Search<TestModel5>( s => s .Explain() //参数可以提供查询的更多详情。 .FielddataFields(fs => fs //对指定字段进行分析 .Field(p => p.Name) .Field(p => p.Dic) ) .From(0) //跳过的数据个数 .Size(50) //返回数据个数 .Query(q => q.Term(p => p.State, 100) // 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型): && q.Term(p => p.Name.Suffix("temp"), "姓名") //用于自定义属性的查询 && q.Bool( //bool 查询 b => b //must should mushnot .Must(mt => mt //所有分句必须全部匹配,与 AND 相同 .TermRange(p => p.Field(f => f.State).GreaterThan("0").LessThan("1"))) //指定范围查找 .Should(sd => sd //至少有一个分句匹配,与 OR 相同 .Term(p => p.State, 32915), sd => sd.Terms(t => t.Field(fd => fd.State).Terms(new[] { 10, 20, 30 })), //多值 //|| //sd.Term(p => p.priceID, 1001) //|| //sd.Term(p => p.priceID, 1005) sd => sd.TermRange(tr => tr.GreaterThan("10").LessThan("12").Field(f => f.State)), //出入的时间必须指明时区 sd => sd.DateRange(tr => tr.GreaterThan(DateTime.Now.AddDays(-1)).LessThan(DateTime.Now).Field(f => f.CreateTime)) ) .MustNot(mn => mn//所有分句都必须不匹配,与 NOT 相同 .Term(p => p.State, 1001) , mn => mn.Bool( bb => bb.Must(mt => mt .Match(mc => mc.Field(fd => fd.Name).Query("至尊")) )) ) ) )//查询条件 .Sort(st => st.Ascending(asc => asc.Id))//排序 //返回特定的字段 //注:2.x 是 sc.Include .Source(sc => sc.Includes(ic => ic .Fields( fd => fd.Name, fd => fd.Id, fd => fd.CreateTime))) );
分页、 深度分页
搜索时通过 from+size 控制分页,但是由于底层机制,深度分页将造成更大的性能消耗。所以 es 默认限制 from+size⇐10000
想要更深的分页,只能通过上页结果作为条件进行翻页。
var response=_client.Search<TestModel5>(s => s.Query(q => q.Term(t => t.Field(fd => fd.State).Value(1))) .Size(1000) .Sort(st => st.Descending(ds => ds.Id)) .SearchAfter(new object[] { 10,//上一次结果排序的最后 ID 值 //可以是多个排序字段的值 }));
扫描和滚屏(用于非实时的获取大量数据)
5.x 中支持并发扫描
Action<int> sc1 = (id) => { string scrollid = ""; //todo:5.x 多了 Slice 设置 移除 SearchType.Scan var result = _client.Search<TestModel5>(s => s.Index(indexName).Query(q => q.MatchAll()) .Size(15) .Sort(st=>st.Descending(ds=>ds.Id)) .Scroll("1m") //id 从 0 开始 0,1,2... //length=max //例:max=3 id=0,id=1,id=2 .Slice(sl => sl.Id(id).Max(3)) ); //得到滚动扫描的 id scrollid = result.ScrollId; foreach (var info in result.Documents) { Console.WriteLine(info.Id + " - " + " -批次 count " + result.Documents.Count + " - 线程"+Thread.CurrentThread.ManagedThreadId); } while (true) { //执行滚动扫描得到数据 返回数据量是 result.Shards.Successful*size(查询成功的分片数*size) var result1 = _client.Scroll<TestModel5>("1m", scrollid); if (result1.Documents == null || !result1.Documents.Any()) break; foreach (var info in result1.Documents) { Console.WriteLine(info.Id + " - " +" -批次 count "+ result1.Documents.Count+ " - 线程" + Thread.CurrentThread.ManagedThreadId); } //得到新的 id scrollid = result1.ScrollId; } }; var t1= Task.Factory.StartNew(() => { sc1(0); }); var t2= Task.Factory.StartNew(() => { sc1(1); }); var t3= Task.Factory.StartNew(() => { sc1(2); }); t1.Wait(); t2.Wait(); t3.Wait();
多查询、排序条件拼接
bool useStateDesc = true; //must 条件 var mustQuerys = new List<Func<QueryContainerDescriptor<TestModel5>, QueryContainer>>(); //Deleted mustQuerys.Add(mt => mt.Term(tm => tm.Field(fd => fd.Deleted).Value(false))); //CreateTime mustQuerys.Add(mt => mt.DateRange(tm => tm.Field(fd => fd.CreateTime).GreaterThanOrEquals(DateTime.Now.AddDays(-1)).LessThanOrEquals(DateTime.Now))); //should 条件 var shouldQuerys = new List<Func<QueryContainerDescriptor<TestModel5>, QueryContainer>>(); //state shouldQuerys.Add(mt => mt.Term(tm => tm.Field(fd => fd.State).Value(1))); shouldQuerys.Add(mt => mt.Term(tm => tm.Field(fd => fd.State).Value(2))); //排序 Func<SortDescriptor<TestModel5>, IPromise<IList<ISort>>> sortDesc = sd => { //根据分值排序 sd.Descending(SortSpecialField.Score); //排序 if (useStateDesc) sd.Descending(d => d.State); else sd.Descending(d => d.Id); return sd; }; var result2 =_client.Search<TestModel5>(s => s .Index(indexName) .Query(q => q.Bool(b => b.Must(mustQuerys).Should(shouldQuerys))) .Size(100) .From(0) .Sort(sortDesc) );
得分控制
//使用 functionscore 计算得分 var result1 = _client.Search<TestModel5>(s => s .Query(q => q.FunctionScore(f => f //查询区 .Query(qq => qq.Term(t => t.Field(fd => fd.State).Value(1)) || qq.Term(t => t.Field(fd => fd.State).Value(2)) ) .Boost(1.0) //functionscore 对分值影响 .BoostMode(FunctionBoostMode.Replace)//计算 boost 模式 ;Replace 为替换 .ScoreMode(FunctionScoreMode.Sum) //计算 score 模式;Sum 为累加 //逻辑区 .Functions(fun => fun .Weight(w => w.Weight(3).Filter(ft => ft .Term(t => t.Field(fd => fd.State).Value(1))))//匹配 cityid +3 .Weight(w => w.Weight(2).Filter(ft => ft .Term(t => t.Field(fd => fd.State).Value(2))))//匹配 pvcid +2 ) ) ) .Size(3000) .Sort(st => st.Descending(SortSpecialField.Score)) ); //结果中 State=1,得分=3; State=2 ,得分=2 ,两者都满足的,得分=5
聚合
聚合-基本
var result = _client.Search<TestModel5>(s => s .Index(indexName) .From(0) .Size(15) .Aggregations(ag => ag .ValueCount("Count", vc => vc.Field(fd => fd.Id))//总数 .Sum("vendorPrice_Sum", su => su.Field(fd => fd.Id))//求和 .Max("vendorPrice_Max", m => m.Field(fd => fd.Id))//最大值 .Min("vendorPrice_Min", m => m.Field(fd => fd.Id))//最小值 .Average("vendorPrice_Avg", avg => avg.Field(fd => fd.Id))//平均值 .Terms("vendorID_group", t => t.Field(fd => fd.Id).Size(100))//分组 ) );
聚合-分组
var result = _client.Search<TestModel5>(s => s .Index(indexName) .Size(0) .Aggregations(ag => ag .Terms("Group_group", //Group 分组 t => t.Field(fd => fd.Group) .Size(100) .Aggregations(agg => agg .Terms("Group_state_group", //Group_state tt => tt.Field(fd => fd.State) .Size(50) .Aggregations(aggg => aggg .Average("g_g_Avg", av => av.Field(fd => fd.Dvalue))//Price avg .Max("g_g_Max", m => m.Field(fd => fd.Dvalue))//Price max .Min("g_g_Min", m => m.Field(fd => fd.Dvalue))//Price min .ValueCount("g_g_Count", m => m.Field(fd => fd.Id))//总记录数 ) ) .Cardinality("g_count", dy => dy.Field(fd => fd.State))//分组数量 .ValueCount("g_Count", c => c.Field(fd => fd.Id)) ) ) .Cardinality("vendorID_group_count", dy => dy.Field(fd => fd.Group))//分组数量 .ValueCount("Count", c => c.Field(fd => fd.Id))//总记录数 ) //分组 );
复杂聚合分组及结果解析
var mustQuerys = new List<Func<QueryContainerDescriptor<TestModel5>, QueryContainer>>(); mustQuerys.Add(t => t.Term(f => f.Deleted, false)); var result = _client.Search<TestModel5>( s => s.Index(indexName) .Query(q => q .Bool(b => b.Must(mustQuerys)) ) .Size(0) .Aggregations(ag => ag .Terms("Group_Group", tm => tm .OrderDescending("Dvalue_avg")//使用平均值排序 desc .Field(fd => fd.Group) .Size(100) .Aggregations(agg => agg .TopHits("top_test_hits", th => th.Sort(srt => srt.Field(fd => fd.Dvalue).Descending()).Size(1))//取出该分组下按 dvalue 分组 .Max("Dvalue_Max", m => m.Field(fd => fd.Dvalue)) .Min("Dvalue_Min", m => m.Field(fd => fd.Dvalue)) .Average("Dvalue_avg", avg => avg.Field(fd => fd.Dvalue))//平均值 ) ) ) ); var vendorIdGroup = (BucketAggregate)result.Aggregations["VendorID_Group"]; foreach (var bucket1 in vendorIdGroup.Items) { var bucket = (KeyedBucket<TestModel5>)bucket1; var maxPrice = ((ValueAggregate)bucket.Aggregations["vendorPrice_Max"]).Value; var minPrice = ((ValueAggregate)bucket.Aggregations["vendorPrice_Min"]).Value; var sources = ((TopHitsAggregate)bucket.Aggregations["top_vendor_hits"]).Documents<TestModel5>().ToList(); var data = sources.FirstOrDefault(); }
作者:huhangfei
出处:https://www.cnblogs.com/huhangfei/p/7524886.html
本站使用「署名 4.0 国际」创作共享协议,转载请在文章明显位置注明作者及出处。

![【学习强国】[挑战答题]带选项完整题库(2020年4月20日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/timg-300x200.jpg)


![【学习强国】[新闻采编学习(记者证)]带选项完整题库(2019年11月1日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/77ed36f4b18679ce54d4cebda306117e-300x200.jpg)




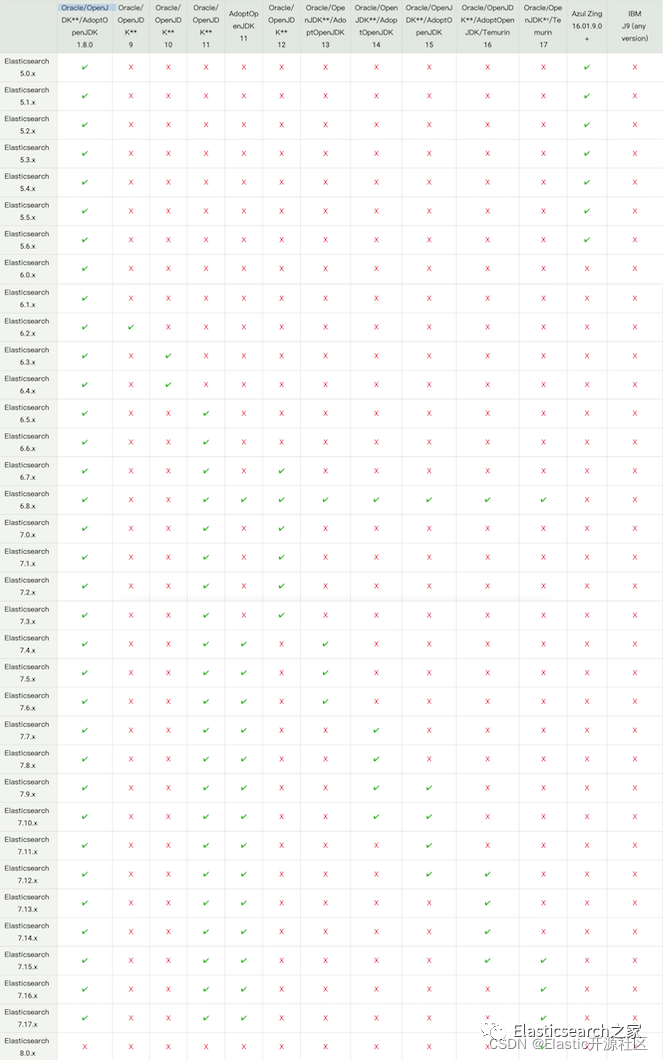

{kind=link}
{kind=link}